verl Tutorial
1 Background
1.1 RL as Dataflow Graph
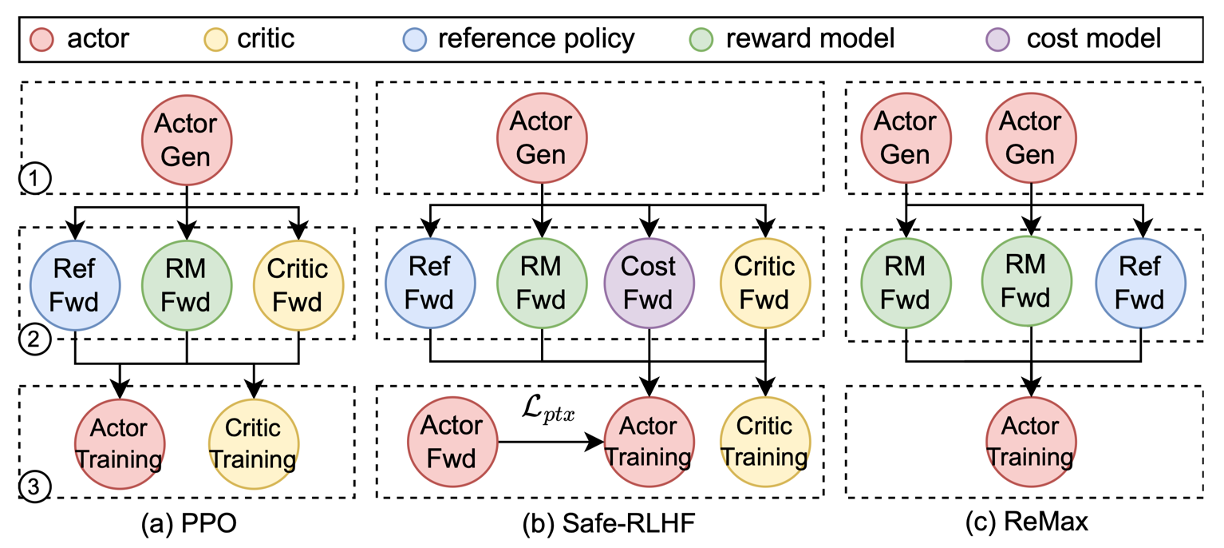
Reinforcement Learning (RL) for LLM Post-Training can typically be modeled as a dataflow graph, consisting of:
- multiple models: actor, critic, reference, reward model, etc.
- multiple stages: generating, preparing experiences, training
- multiple workloads: generation, inference, training
1.2 Implementing Dataflow Graph as Execution Pattern
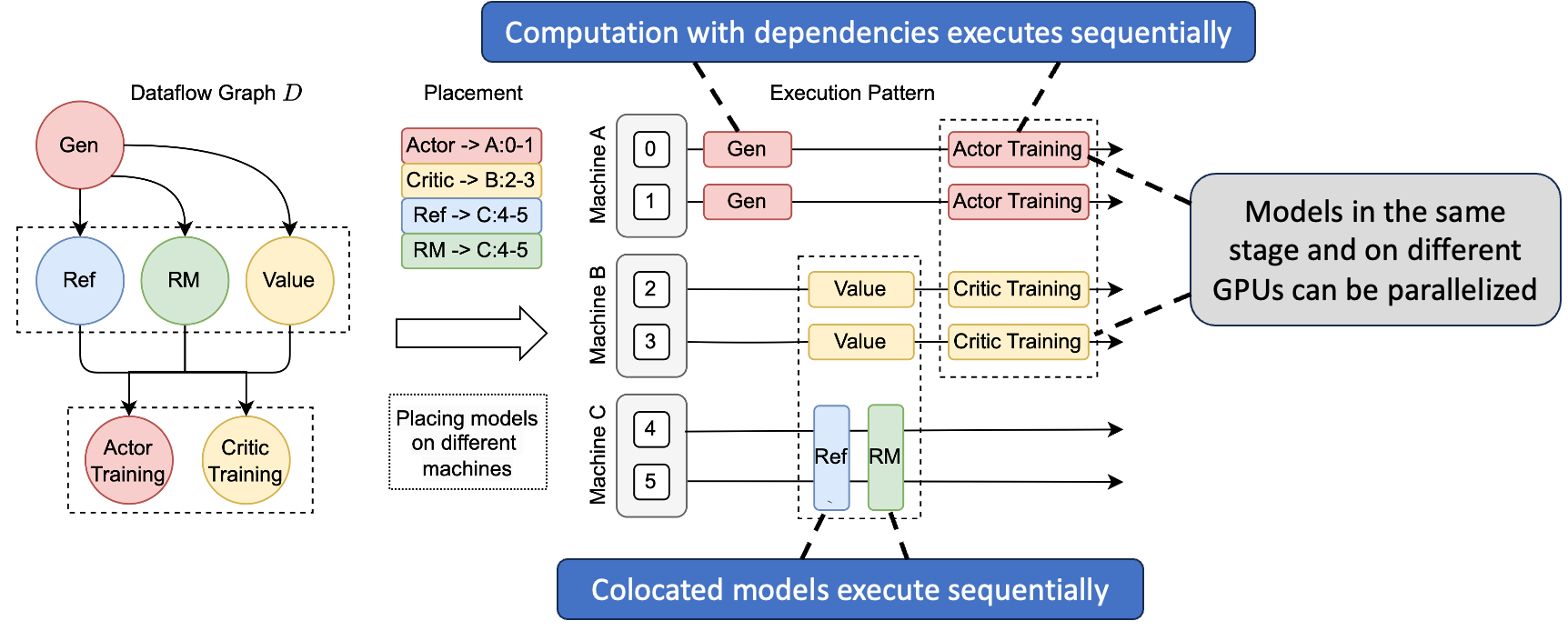
In practice, we should implement the dataflow graph as execution pattern on GPU cluster.
2 verl Code Walkthrough
We take the verl (Sheng et al. 2024) default implementation as an example.
2.1 Entrypoint
verl uses a global resource pool and allocates all the workers (e.g., ActorRollout, Critic) to it by default.
global_pool_id = "global_pool"
resource_pool_spec = {
global_pool_id: ([config.trainer.n_gpus_per_node] * config.trainer.nnodes),
}
mapping = {
Role.ActorRollout: global_pool_id, Role.Critic: global_pool_id,
Role.RefPolicy: global_pool_id, Role.RewardModel: global_pool_id,
}
resource_pool_manager = ResourcePoolManager(
resource_pool_spec=resource_pool_spec, mapping=mapping)
# ...
trainer = RayPPOTrainer(config=config,
resource_pool_manager=resource_pool_manager, # ...
)
trainer.fit()2.2 Spawning Worker Groups
- Each worker group corresponds to
- a
resource_pool(some GPUs); - one or more workers in
class_dict.
- a
wg_dict.spawn()launches one process per GPU.
# `resource_pool_to_cls` is a `dict`
# mapping resource pools to worker classes.
for resource_pool, class_dict in self.resource_pool_to_cls.items():
# ...
wg_dict = self.ray_worker_group_cls(
resource_pool=resource_pool, # ...
)
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
all_wg.update(spawn_wg)
self.wg_dicts.append(wg_dict)2.3 Training Loop: Single-Controller
Between worker procedures, verl adopts a single-controller paradigm to maximize the flexibility, which allows the users to
- focus on the dataflow graph
- without worrying about the distributed implementation.
verl runs the worker procedures sequentially within the global resource pool by default.
for epoch in range(self.config.trainer.total_epochs):
for batch_dict in self.train_dataloader:
batch = DataProto.from_single_dict(batch_dict)
# Stage 1: Generating
gen_batch = batch.pop(...)
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
# Stage 2: Preparing Experiences
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
values = self.critic_wg.compute_values(batch)
reward_tensor = self.rm_wg.compute_rm_score(batch)
# Stage 3: Training
self.critic_wg.update_critic(batch)
self.actor_rollout_wg.update_actor(batch)2.4 Worker Procedure: Multi-Controller
Inside a worker procedure, verl adopts a multi-controller paradigm, i.e., SPMD (Single Program Multiple Data), to maximize the efficiency.
In SPMD, all the processes
- run the same program,
- but process diffrent data based on the distributed environment variables like
RANK.
SPMD is the programming model of most popular distributed methods, e.g.,
- Data Parallelism: DDP, ZeRO, FSDP
- Tensor Parallelism
- Pipeline Parallelism
- Sequence Parallelism
3 SPMD in verl
3.1 How verl Manages the Resources
verl
- spawns a list of
_workers, each of which is a Ray worker running on a GPU - and sets the SPMD environment variables for each worker.
def _init_with_resource_pool(self, resource_pool, ray_cls_with_init):
# ...
rank = -1
for pg_idx, pg in enumerate(sort_placement_group_by_node_ip(pgs)): # Node
for local_rank in range(local_world_size): # GPU
rank += 1
env_vars = {
'WORLD_SIZE': str(world_size), 'RANK': str(rank), # More env vars ...
}
ray_cls_with_init.update_options(
{'runtime_env': {'env_vars': env_vars}})
# ...
worker = ray_cls_with_init(placement_group=pg,
placement_group_bundle_idx=local_rank)
self._workers.append(worker)
# ...3.2 How verl Defines the SPMD Behavior
Taking the ActorRolloutRefWorker.update_actor() as an example:
3.2.1 register
The register decorator adds attrs like dispatch_mode to the func.
def register(dispatch_mode=Dispatch.ALL_TO_ALL, execute_mode=Execute.ALL,
blocking=True, materialize_futures=True):
# ...
def decorator(func):
@wraps(func)
def inner(*args, **kwargs):
if materialize_futures:
args, kwargs = _materialize_futures(*args, **kwargs)
return func(*args, **kwargs)
attrs = {'dispatch_mode': dispatch_mode, 'execute_mode': execute_mode,
'blocking': blocking,}
setattr(inner, MAGIC_ATTR, attrs)
return inner
return decorator3.2.2 dispatch_fn & collect_fn
dispatch_mode defines how verl dispatches the data to and collects the results from the workers.
Here, update_actor
- splits the data uniformly with
chunk - concatenates all the workers’ results with
_concat_data_proto_or_future.
def dispatch_dp_compute_data_proto(worker_group, *args, **kwargs):
# ...
splitted_args, splitted_kwargs = _split_args_kwargs_data_proto(
worker_group.world_size, *args, **kwargs)
return splitted_args, splitted_kwargs
def _split_args_kwargs_data_proto(chunks, *args, **kwargs):
# ...
splitted_args = []
for arg in args:
splitted_args.append(arg.chunk(chunks=chunks))
# Similar for kwargs ...
return splitted_args, splitted_kwargs
def collect_dp_compute_data_proto(worker_group, output):
# ...
return _concat_data_proto_or_future(output)3.2.3 execute_fn
Here, update_actor uses execute_all to dispatch the uniformly splitted data to all the workers and issues the remote calls.
predefined_execute_mode_fn = {
Execute.ALL: {'execute_fn_name': 'execute_all'}, # ...
}
class RayWorkerGroup:
def execute_all(self, method_name: str, *args, **kwargs):
return self.execute_all_async(method_name, *args, **kwargs)
def execute_all_async(self, method_name: str, *args, **kwargs):
length = len(self._workers)
result = []
for i in range(length):
sliced_args = tuple(arg[i] for arg in args)
sliced_kwargs = {k: v[i] for k, v in kwargs.items()}
remote_call = getattr(self._workers[i], method_name)
result.append(remote_call.remote(*sliced_args, **sliced_kwargs))
return result3.2.4 func_generator
*_fn are used in func_generator to generate the actual caller.
def func_generator(self, method_name,
dispatch_fn, collect_fn, execute_fn, blocking):
def func(*args, **kwargs):
args, kwargs = dispatch_fn(self, *args, **kwargs)
output = execute_fn(method_name, *args, **kwargs)
if blocking:
output = ray.get(output)
output = collect_fn(self, output)
return output
return funcReferences